博主辛苦了,我要打赏银两给博主,犒劳犒劳站长。

【摘要】很多时候,我们都需要查询已存在于 tbl_a 表而不存在于 tbl_b 的数据,那么都有哪些方法呢,本文记录了三种方法,并比较它们的优劣。
首先给出两张表 tbl_a 和 tbl_b ,表内容如下所示:

采用 not in 方式优点在于 sql 语言很好理解,一看就能够看懂语句的意思,缺点在于当数据量较大的时候,查询时间长,即其 sql 效率低,当然在数据量较小的时候还是可以使用的。
select distinct a.name from tbl_a a where a.name not in (select distinct b.name from tbl_b b);
这种方法的效率比 not in 的高,但是不太好理解,不过如果将它想象成一张关联后的大表,把 b 表中不存在的数据去掉即能够很好的理解。
select distinct a.name from tbl_a a left join tbl_b b on a.name = b.name where b.name is null;
这种方法,是最为高效的,而且也是比较好理解的,建议大家一定要记住这一方法!
exists(sql 返回结果集为真)、not exists(sql 不返回结果集为假)
效率对比:select 1 > select name > select *
select distinct a.name from tbl_a a where not exists(select 1 from tbl_b b where a.name = b.name);
最后查询出来的结果都是:
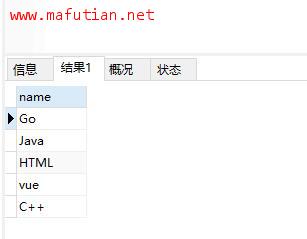
当然除了这三种方式之外,肯定还有其他方法,但是咱们不需要记住这么多,因为脑子可能记不住。
版权归 马富天个人博客 所有
本文标题:《sql 语句查询存在于一张表中而不存在于另外一张表数据的三种最常用方法》
本文链接地址:http://www.mafutian.com/416.html
转载请务必注明出处,小生将不胜感激,谢谢! 喜欢本文或觉得本文对您有帮助,请分享给您的朋友 ^_^
顶0
踩0
第 1 楼 北京安装监控 2019-05-06 20:32:35 暂无分享
| 评论审核未开启 |























|
||
|
|